Azure map, replace earlier mapping technology provided by Microsoft which was called "Bing Maps".
Recently I had chance to look into Azure map routing feature (calculating route between two points) for my work. There fore, I thought I should write some blog about this new mapping technology by Microsoft.
My requirement was to calculate routed distance between two post codes in UK. In order to do this I had to use Azure Map routing APIs.
Before you start, first thing you must do is create a Azure Map account in your Azure portal.
In Azure portal, market place, search for "Azure Maps".

Then click on "Create" button under that. Fill the basic information for the account as shown in following screen shot.

If you wish you can fill other options as well, but for simplicity, I will keep them default.
In order to authenticate for Azure Maps, you can use either Microsoft Entra ID (active directory) permissions or can use shared key. For simplicity I will be using Shared Key Authentication.

You will see a section like above. Copy the Primary Key (or secondary key, either will work) and store in a safe place.
Now that we have an Azure Map and shared key to use it, we will now go and build the demo app for routing.
Console APP:
To keep it simple I'm going to create .Net core console application:

https://www.nuget.org/packages/Azure.Maps.Routing
There fore install above nuget package to the newly create project.
There fore install above nuget package to the newly create project.
NuGet\Install-Package Azure.Maps.Routing
Note that package is in pre-release as of now (25/01/2025), so you need to tick "Include pre-releases" box on the package manager window.
Initiate route client object:
//Create a MapsRoutingClient that will authenticate through Subscription Key (Shared key) AzureKeyCredential credential = new AzureKeyCredential("<My Subscription Key>"); MapsRoutingClient client = new MapsRoutingClient(credential);
Replace the "My subscription key" part with your key from the Azure Maps Account. It is good idea to put this in configuration file and read it from there.
Note that I'm using shared key authentication, which is the simplest form of authentication, but you can use AAD (Azure Active Directory) authentication also. When using AAD authentication, you configure permissions on Azure Maps account for each AAD user.
Now I want user to input two post code (source and destination), so lets do the code for that:
Console.WriteLine("Enter the start postcode:");
string startPostcode = Console.ReadLine();
Console.WriteLine("Enter the end postcode:");
string endPostcode = Console.ReadLine();
Now we need to convert post code to geo coordinates (latitude and longitude) before sending them to Azure Maps API.
Simplest way to get geo coordinates from post code is use service like postcode.io. Postcodes.io is a free, open-source API specifically designed for UK postcodes.
Let's create a helper class to help with getting geo coordinates. Let's call it "PostCodeGeocoder".
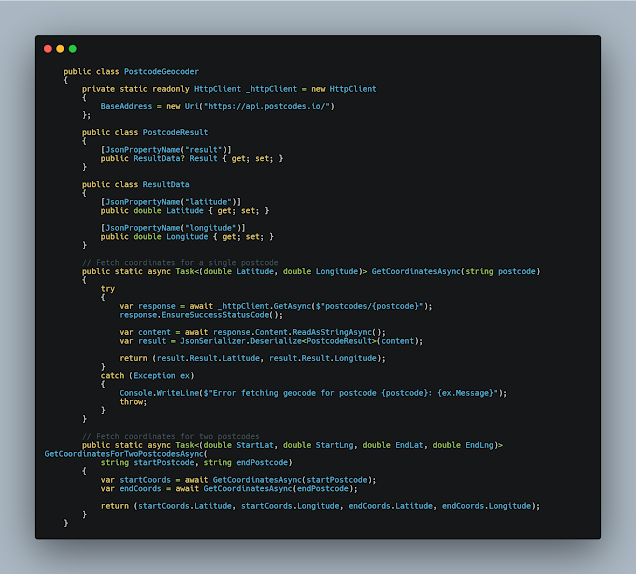
First part of the class is setting the base address for postcode.io api.
private static readonly HttpClient _httpClient = new HttpClient
{
BaseAddress = new Uri("https://api.postcodes.io/")
};
Then we have two inner classes to hold the latitude and longitude:
public class PostcodeResult
{
[JsonPropertyName("result")]
public ResultData? Result { get; set; }
}
public class ResultData
{
[JsonPropertyName("latitude")]
public double Latitude { get; set; }
[JsonPropertyName("longitude")]
public double Longitude { get; set; }
}
(Note that they have Json attribute to deserialize them correctly)
Code next to that is the heart of the class which brings the coordinates from postcode.io:
public static async Task<(double Latitude, double Longitude)> GetCoordinatesAsync(string postcode)
{
try
{
var response = await _httpClient.GetAsync($"postcodes/{postcode}");
response.EnsureSuccessStatusCode();
var content = await response.Content.ReadAsStringAsync();
var result = JsonSerializer.Deserialize<PostcodeResult>(content);
return (result.Result.Latitude, result.Result.Longitude);
}
catch (Exception ex)
{
Console.WriteLine($"Error fetching geocode for postcode {postcode}: {ex.Message}");
throw;
}
}
Last part call the above method for start and end post codes:
// Fetch coordinates for two postcodes
public static async Task<(double StartLat, double StartLng, double EndLat, double EndLng)> GetCoordinatesForTwoPostcodesAsync(
string startPostcode, string endPostcode)
{
var startCoords = await GetCoordinatesAsync(startPostcode);
var endCoords = await GetCoordinatesAsync(endPostcode);
return (startCoords.Latitude, startCoords.Longitude, endCoords.Latitude, endCoords.Longitude);
}
Now let's use our helper class in main program:
var result = await PostcodeGeocoder.GetCoordinatesForTwoPostcodesAsync(startPostcode, endPostcode);
Console.WriteLine($"Start Coordinates: Latitude = {result.StartLat}, Longitude = {result.StartLng}");
Console.WriteLine($"End Coordinates: Latitude = {result.EndLat}, Longitude = {result.EndLng}");
Ok. now we got all our preliminaries.
Route matrix is as it sounds, is a 2D matrix (array).
You can enter as many origins (starting points) and as many as destinations (end points) to it. For example, if you enter 2 origins and 2 destinations, you will get 4 resulting routes.
For simplicity we will use one origin pint and one destination:
// prepare our geolocations for origins and destinations (we just use one, but can use many as you like)
List<GeoPosition> origins = new List<GeoPosition>() { new GeoPosition(result.StartLng, result.StartLat) };
List<GeoPosition> destination = new List<GeoPosition>() { new GeoPosition(result.EndLng, result.EndLat) };
Then you can instantiate route matrix:
// Instantiate route matrix query
RouteMatrixQuery routeMatrixQuery = new RouteMatrixQuery
{
Origins = origins,
Destinations = destination
};
If you prefer you can override default options for route matrix by using RouteMatrixOptions class:
// Instantiate route matrix options
RouteMatrixOptions routeMatrixOptions = new RouteMatrixOptions(routeMatrixQuery)
{
RouteType = RouteType.Economy
};
RouteMatrixOptions class allows you to configure your route, how you want to travel and route output. For example "TravelMode" define which travelling mode (car, van, buts, walk) you will be using.
See class reference for more detail.
You can call Route Matrix request synchronously and asynchronously.
If you using synchronous mode, matrix element count should be less than 100.
I.e. : origins count * destination count should be <= 100
Calling Synchrounously:
Response<RouteMatrixResult> reqResult = client.GetImmediateRouteMatrix(routeMatrixQuery);
Calling Synchronously (with options):
Response<RouteMatrixResult> reqResult = client.GetImmediateRouteMatrix(options);
You can use asynchronous calling if the matrix has more than 100 elements. However, asynchronous method also only support 700 elements maximum.
Calling Asynchronously:
// Invoke an long-running operation route matrix request and directly wait for completion
GetRouteMatrixOperation reqResult = client.GetRouteMatrix(WaitUntil.Completed, routeMatrixOptions);
var routeResults = reqResult.Value;
Above will wait for completion and output results.
Printing results:
// Route matrix result summary
Console.WriteLine($"Total request routes: {0}, Successful routes: {1}",
routeResults.Summary.TotalRoutes,
routeResults.Summary.SuccessfulRoutes);
// Route matrix result
foreach (IList<RouteMatrix> routeResult in routeResults.Matrix)
{
Console.WriteLine("Route result:");
foreach (RouteMatrix route in routeResult)
{
RouteLegSummary summary = route.Summary;
Console.WriteLine($"Travel time: {summary.TravelTimeInSeconds} seconds");
Console.WriteLine($"Travel length: {summary.LengthInMeters} meters");
Console.WriteLine($"Departure at: {summary.DepartureTime.ToString()} meters");
Console.WriteLine($"Arrive at: {summary.ArrivalTime.ToString()} meters");
}
}
Getting Asynchronous results later:
Results are saved in Azure for 14 days. There fore you can access results later using the operation id. You need to save this operation id if you are going to use this method.
// Invoke an async route matrix request and get the result later via assigning `WaitUntil.Started`
GetRouteMatrixOperation operation = client.GetRouteMatrix(WaitUntil.Started, routeMatrixOptions);
// Get the operation ID and store somewhere
string operationId = operation.Id;
Then you can use the operation id to retrieve results.
// Within 14 days, users can retrieve the cached result with operation ID
// The `endpoint` argument in `client` should be the same!
GetRouteMatrixOperation newRouteMatrixOperation = new GetRouteMatrixOperation(client, operationId);
Response<RouteMatrixResult> reqResult= newRouteMatrixOperation.WaitForCompletion();
Results:
You will get result like below when you run the application:

Note that travel length is in meters, if you want in miles, you will have to do the conversion. Unlike BingMaps there is no option to get results in specific units.
Used following as a reference: https://github.com/Azure/azure-sdk-for-net/blob/main/sdk/maps/Azure.Maps.Routing/samples/RouteMatrixSamples.md










